Introduction
If you're building on top of LLMs right now, you've probably noticed how much the pricing landscape has changed. A couple of years ago, your options were basically OpenAI or running your own models on expensive GPU rigs. Today, there's a genuine marketplace. Open-source models have gotten remarkably capable, specialized inference providers are multiplying, and the economics of running AI have shifted in ways worth paying attention to.
Why does this matter? Inference costs directly affect your product margins, your runway, and how fast you can iterate. Even a 1–2x pricing difference between providers can meaningfully impact your AI project's viability. But comparing providers is trickier than it looks—some charge per token, others offer flat-rate subscriptions, and less obvious costs like cold starts and GPU idle time can add up.
We dug into seven major inference providers, looking past the headline pricing to figure out what you'd actually pay across real usage patterns. This guide should help you pick the provider that genuinely fits your needs not just the one with the flashiest pricing page.
The Modern Pricing Landscape
Today's inference market has split into two camps: per-token pricing and flat-rate subscriptions. The model you choose fundamentally changes how you think about costs.
With per-token pricing (think OpenAI and similar providers), you pay for every token you process. Sounds simple. Until you realize that the same model from different providers can have wildly different price tags. A model that runs $0.50 per million tokens on one platform might cost $2.00 on another, depending on how each provider has optimized their infrastructure.
Flat-rate pricing flips the script entirely. You pay a fixed monthly fee and get access to a certain tier of compute—run as many tokens as your infrastructure can handle without extra charges. This approach really took off as open-source models matured, letting providers offer predictable costs that startups and variable-usage apps love.
There's no one-size-fits-all winner here. If you're running a low-volume production app that only processes a few thousand tokens per day, per-token pricing probably makes more sense. But for research teams, dev environments, or apps with unpredictable traffic spikes, flat-rate pricing tends to give you better value and fewer billing surprises.
Provider Pricing Comparison: The 2026 Snapshot
Here's how the major providers stack up as of March 2026. Keep in mind that these are typical prices for popular models; your mileage may vary by model and region.
| Provider | Pricing Model | Input Cost | Output Cost | Key Features |
|---|---|---|---|---|
| Featherless.ai | Flat-rate Monthly | $10-75/mo unlimited tokens | 25,000+ models, serverless, no token limits | |
| OpenRouter (GPT-5 mini) | Per-token | $0.03/1K tokens | $0.06/1K tokens | Multi-provider access, rate limiting flexibility |
| OpenRouter (Claude Sonnet 4.6) | Per-token | $0.003/1K tokens | $0.015/1K tokens | Same platform, different rates per model |
| Together.ai (Llama 4 Maverick) | Per-token | $0.00027/1K tokens | $0.00085/1K tokens | Open-source focus, competitive pricing |
| Together.ai (Mistral Large 3) | Per-token | $0.004/1K tokens | $0.008/1K tokens | Fast inference, variable pricing by model |
| AWS Bedrock (Claude Opus 4.6) | Per-token | $0.005/1K tokens | $0.025/1K tokens | Enterprise features, on-demand scaling |
| AWS Bedrock (Llama 4 Maverick) | Per-token | $0.00195/1K tokens | $0.00256/1K tokens | Different models, different costs |
| Fireworks AI (Llama 4 Maverick) | Per-token | $0.00022/1K tokens | $0.00088/1K tokens | Optimized inference, fast API |
| Replicate (Llama 4 Maverick) | Per-second | $0.000350/second | Diverse model catalog, transparent pricing | |
A few things jump out right away. Proprietary models like GPT-5 mini carry premium price tags, typically 10–30x higher than open-source alternatives. But even among open-source models, pricing varies—Llama 4 Maverick on Together.ai costs roughly 20% more for input tokens than on Fireworks AI, even though it's the exact same model.
Why such big price gaps for the same model? It comes down to infrastructure efficiency, business model, and scale. Fireworks AI, for example, has built custom kernels and inference engines that squeeze more performance out of each GPU. Replicate runs more like a marketplace where different providers offer the same model at competing prices.
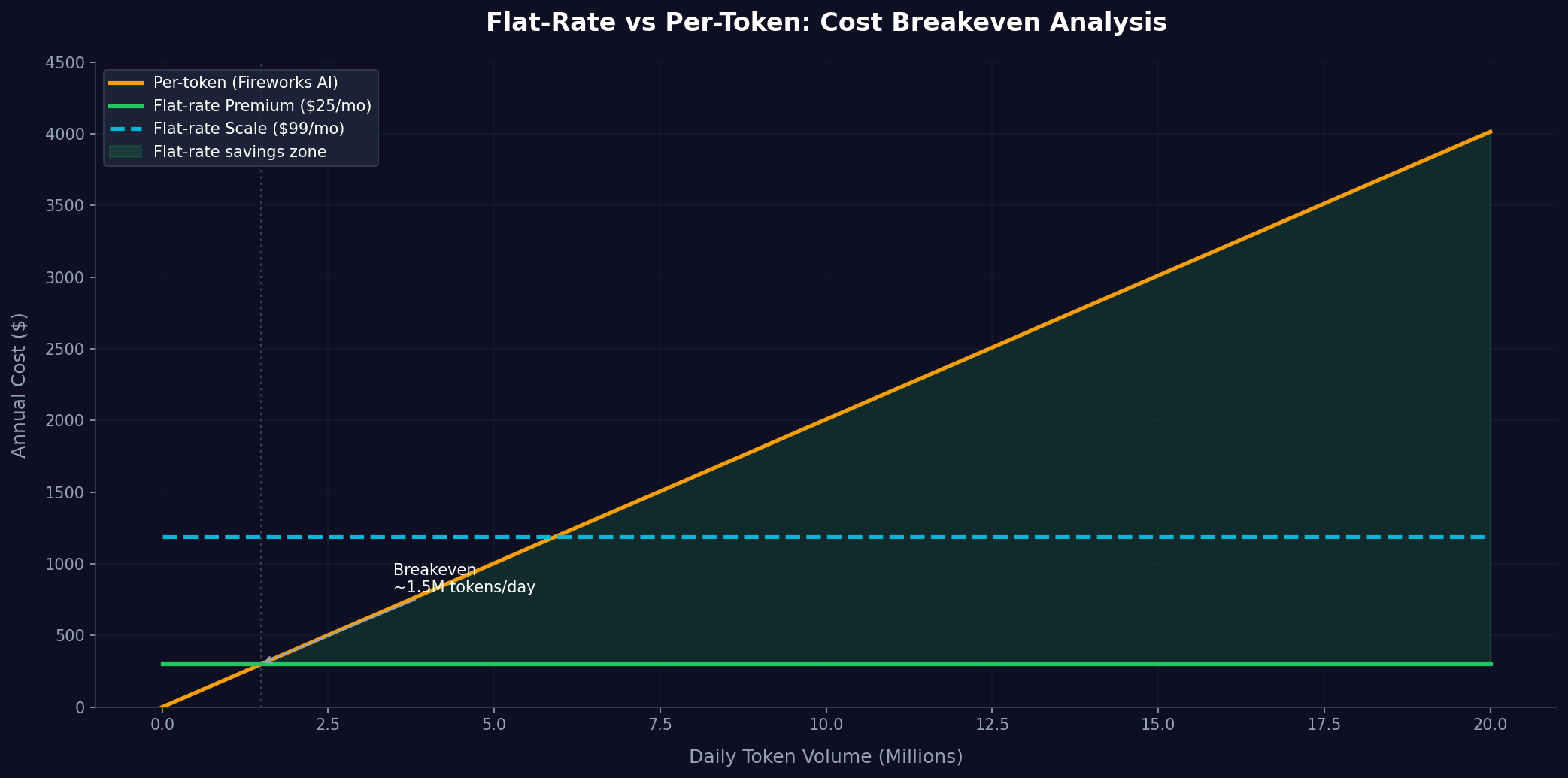
Understanding Flat-Rate vs Per-Token Economics
Let's ground this in real scenarios to understand what pricing models actually mean for your budget.
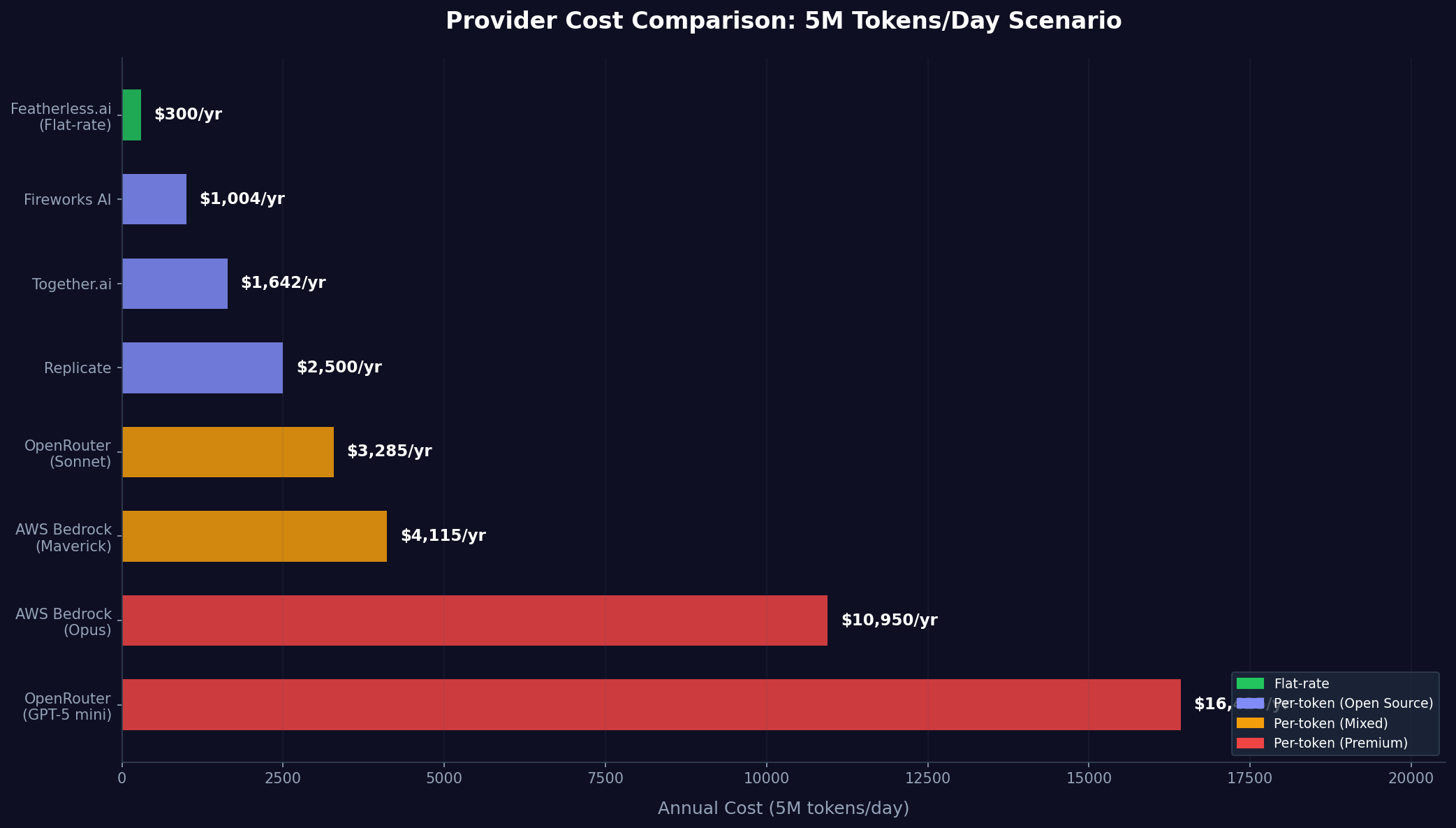
Consider a production customer support chatbot processing 5,000,000 tokens daily across multiple channels. Using Llama 4 Maverick on per-token providers, you'd expect costs around:
| Provider | Daily Cost | Annual Cost |
|---|---|---|
| Fireworks AI | ~$2.75/day | $1,004/year |
| Together.ai | ~$4.50/day | $1,642/year |
| AWS Bedrock | ~$11.28/day | $4,115/year |
Now consider the same workload on Featherless.ai's $25/month Premium tier. Your annual cost is a fixed $300 regardless of whether you process 5,000,000 or 10,000,000 tokens daily. For this moderate-volume application, flat-rate pricing is 1.5-14x cheaper. Note that flat-rate plans come with concurrency limits—Featherless.ai's Premium tier allows 4 concurrent requests, while Scale supports 8 or more. For a moderate-volume application like this, 4 concurrent slots are generally sufficient, but teams running high-throughput production workloads with strict latency requirements should evaluate whether their peak concurrency fits within their chosen tier.
However, assume instead you're building a personal productivity assistant handling 5,000 tokens daily. Using the same providers:
| Provider | Daily Cost | Annual Cost |
|---|---|---|
| Fireworks AI | ~$0.00275/day | $1.00/year |
| Together.ai | ~$0.005/day | $1.64/year |
| Featherless.ai Basic | — | $120/year |
Here, per-token pricing wins by a wide margin. The calculation shifts further if you need premium model access. Processing 100,000 tokens daily with GPT-5 mini via OpenRouter costs roughly $135/month in per-token charges, whereas using a high-performance open-source model at flat-rate pricing costs a fraction of that.
The economic inflection point depends on your model choice and token volume. Open-source models achieve cost parity with flat-rate pricing at lower volumes than proprietary models. The broader insight: flat-rate pricing inverts the economics, making variable token costs irrelevant and shifting the question to infrastructure capacity rather than usage.
Hidden Costs That Impact Your TCO
Per-token pricing looks simple on paper, but several hidden costs can change what you actually end up paying:
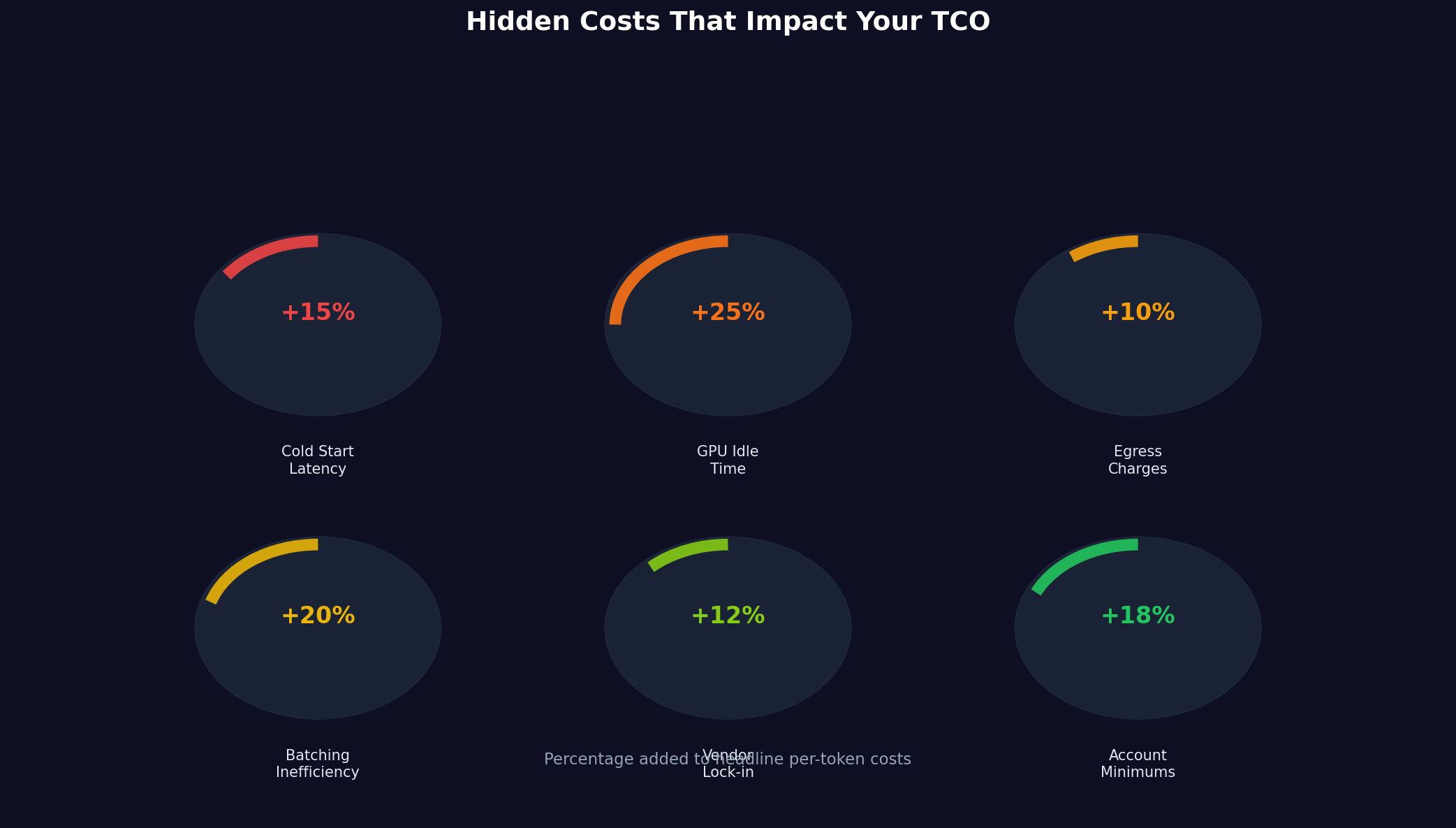
Cold start latency affects applications requiring sub-second response times. When a provider hasn't loaded your model into GPU memory, the first request incurs a delay as the model initializes—typically under 5 seconds for serverless providers like Featherless.ai, though it can vary by model size. Some providers charge nothing for this delay; others charge full per-token rates. For interactive applications, cold starts represent real user experience degradation.
GPU idle time applies to on-demand providers where you reserve compute resources. Reserved instances on AWS or other cloud platforms charge per hour whether your model runs or not. Using a $2.00/hour GPU for 10 minutes of traffic can cost $0.33, whereas a per-token provider with shared infrastructure spreads this cost across thousands of customers.
Egress charges appear for data leaving the provider's network. AWS Bedrock, for instance, charges $0.09 per GB for data exceeding 100GB/month. For applications with large token volumes and long generation lengths, this can add 5-10% to per-token costs. Featherless.ai includes egress within flat-rate pricing.
Request overhead and batching inefficiency silently inflate costs. A provider with poor request multiplexing might handle fewer tokens per GPU per hour, effectively raising per-token costs. Some providers impose minimum request sizes or latency requirements that force inefficient batching.
Vendor lock-in costs matter over time. Switching providers requires code changes, potentially business logic modifications if providers differ in inference speeds or output consistency. These switching costs effectively increase your committed vendor expense.
Account minimum commitments appear at enterprise providers. AWS Bedrock and similar services might require $10,000-50,000 annual commitments for volume discounts. For early-stage companies, these minimums represent sunk costs even if usage remains low.
Calculating Your True Total Cost of Ownership
Determining which provider offers the best value requires calculating your specific total cost of ownership. This involves estimating token volume, identifying your required model(s), and accounting for hidden costs.
Step 1: Estimate your token volume. Calculate tokens daily across all use cases. A rough approximation: 1,000 words = 1,330 tokens. Track both input and output tokens since many providers price them differently. Build conservative estimates, then 2x and 3x multiples to understand how costs scale.
Step 2: Map your model requirements. Which models does your application require? Do you need GPT-5 mini's capabilities, or can open-source Mistral or Llama serve your use case? This choice alone can change costs by 10-100x. Building your MVP with open-source models often makes financial sense even if you plan to upgrade later.
Step 3: Account for your usage pattern. Does your application have steady throughput or spiky demand? Flat-rate providers shine with unpredictable spikes because overage doesn't increase costs. Per-token providers penalize spikes proportionally but reward consistent low usage.
Step 4: Evaluate hidden costs specific to your deployment. Will you hit cold starts frequently? Do you need sub-second latency requiring reserved capacity? Is egress bandwidth significant for your application? These factors add 10-50% to headline per-token costs.
Step 5: Project multi-year costs. Inference prices have declined 30-50% annually for open-source models. Building with providers that maintain competitive pricing and don't charge lock-in fees provides flexibility to optimize as the market evolves.
Let's apply this framework to three scenarios.
Scenario 1: Research Team. A group of five ML engineers experimenting with different models and approaches, processing roughly 50,000 tokens daily across multiple models: high variability, occasional large batches. Featherless.ai Premium at $25/month ($300/year) works well here—it supports unlimited tokens and model experimentation without tracking costs per request. The Premium tier's 4 concurrent request slots are a reasonable fit for a research team of this size, since engineers rarely run simultaneous requests at all times. Teams that do run heavy parallel workloads can upgrade to Scale ($75/month) for 8+ concurrent slots.
Scenario 2: Production Chat Application. A customer support bot handling 10,000,000 tokens daily with Llama 4 Maverick, steady predictable traffic, single model. Fireworks AI at ~$0.00055/1K tokens = roughly $2,008/year. Featherless.ai Scale at $99/month = $1,188/year. Featherless wins on cost by about 1.7x. One practical consideration: the Scale tier supports 8+ concurrent requests. For a production chatbot, you'll want to confirm that your peak concurrent user load fits within that limit, or implement request queuing. For most small-to-mid-scale support bots, 8 concurrent slots handle traffic comfortably, but high-traffic applications may need to plan accordingly.
Scenario 3: Premium Productivity Tool. A user-facing application with 100,000 tokens daily, requiring GPT-5 mini quality output, willing to pay for premium. OpenRouter GPT-5 mini per-token pricing costs ~$1,640/year. There's no flat-rate equivalent for GPT-5 mini, so per-token is your only option at this provider. However, evaluating open-source alternatives (Llama 4 Maverick, Mistral Large 3) on a flat-rate plan costs just $300/year with strong performance.
Cost Optimization Strategies
Once you understand the pricing landscape, there are several practical ways to cut inference costs without giving up quality.
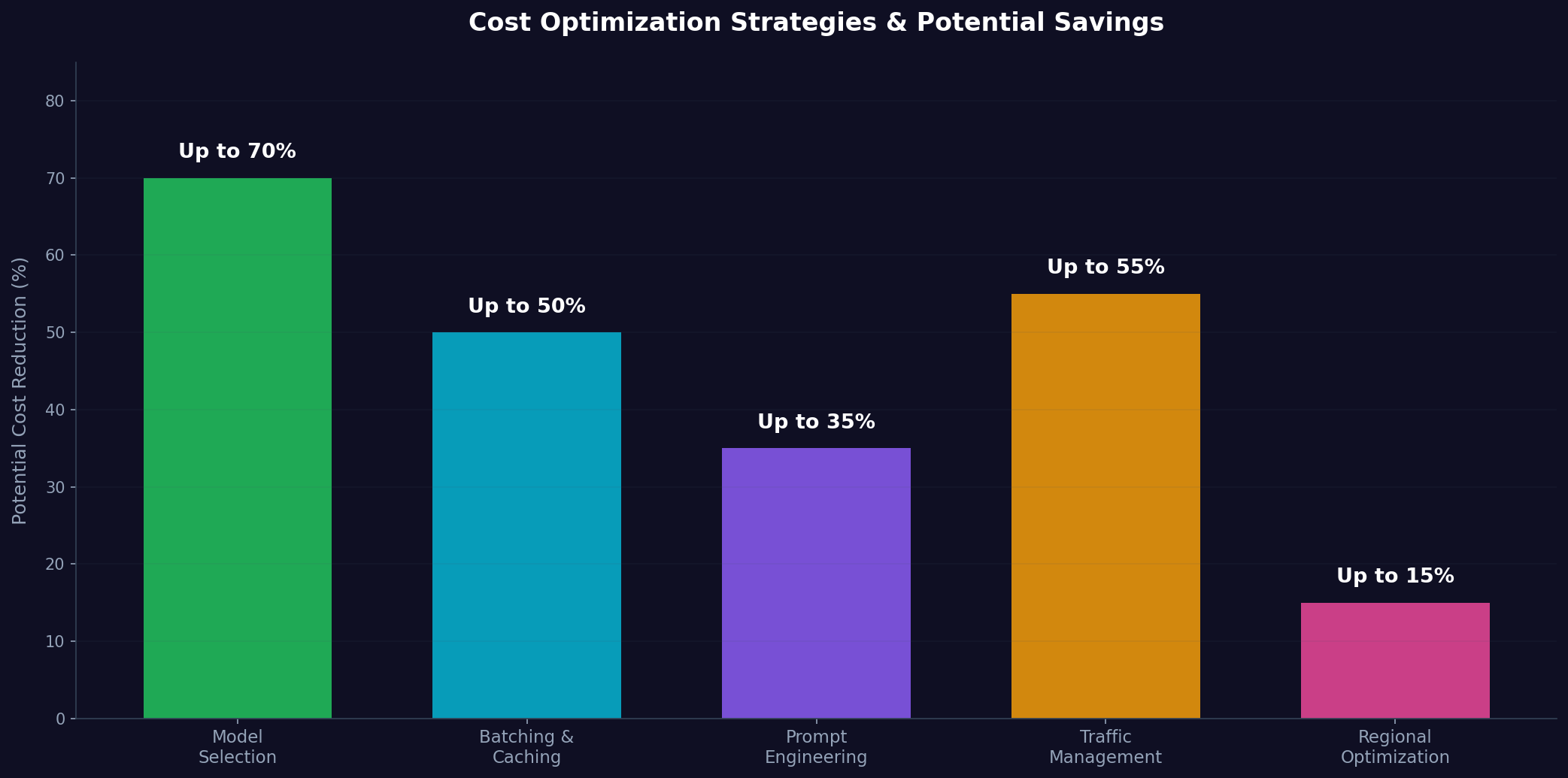
Model selection. This is the highest-impact lever. Upgrading from Mistral Small ($0.00014/1K tokens) to Llama 4 Maverick ($0.00055/1K tokens) increases costs nearly 4x, but quality improvements often don't scale linearly. Benchmarking your specific task against models reveals sweet spots where cost and performance align. Smaller quantized models (int8, int4) can cost 50–70% less than full-precision versions with minimal quality loss.
Batching and caching. Group requests together where latency permits. On per-token providers, parallelizing up to your rate limit is straightforward. On flat-rate providers like Featherless.ai, be mindful of your concurrency cap—use a semaphore or request queue to stay within your tier's concurrent slot limit (e.g., 4 on Premium, 8+ on Scale). Caching repeated prompts avoids re-processing identical context. For applications with common knowledge bases or templates, caching can reduce token costs by 30-50%.
Prompt engineering for efficiency. Concise prompts cost less than verbose ones. Techniques like in-context learning vs fine-tuning can reduce required tokens. Using chain-of-thought prompting or structured output formats reduces ambiguous generations that require follow-up requests.
Traffic management. Route simple queries to cheaper models; reserve expensive models for complex requests. Implement fallback mechanisms where GPT-5 mini handles edge cases while Llama handles the 95% of straightforward requests. This hybrid approach can cut average costs by 40-60%.
Regional and off-peak optimization. Some providers offer regional pricing variations. Processing non-urgent batch inference during off-peak hours can yield discounts at providers offering time-based pricing (currently rare, but emerging).
Practical Implementation: Cost-Aware API Calls
When implementing cost-effective inference, there are three key patterns worth adopting:
Pattern 1: Per-Token Cost Monitoring
On Featherless.ai, every API call costs zero additional tokens beyond your monthly subscription. The same query on OpenRouter with Claude would cost approximately $0.005 at current Claude Sonnet 4.6 pricing. Building a cost-tracking wrapper around your API calls helps you monitor usage—on flat-rate plans this is purely informational, but on per-token providers it's essential for budget management.
Pattern 2: Smart Model Selection Based on Cost
Route 60% of requests to Mistral Small ($0.00028/1K tokens), 30% to Llama 4 Maverick ($0.00055/1K tokens), and 10% to Mistral Large 3 ($0.004/1K tokens) based on complexity. Average cost per request drops 40–50% compared to routing all requests to the highest-capability model. Map task complexity (simple, moderate, complex) to model tiers, with budget-priority flags to override toward cheaper models when margins matter.
Pattern 3: Batch Processing for Cost Efficiency
Process multiple requests in sequence with shared system prompts. If your provider supports prompt prefix caching, reusing the same system prompt across requests can cut input token costs significantly. This pattern also keeps your code clean and makes large batch jobs easy to manage. For example, analyzing 1,000 customer reviews with Mistral Small using batch processing is dramatically cheaper than sending them individually to a premium model.
Featherless.ai: A Different Approach to Inference Costs
Featherless.ai does something different from most providers: instead of charging per token, they offer flat monthly rates with unlimited tokens. You pick a tier—$10/month for Basic (hobby projects, 2 concurrent requests, models up to 15B parameters), $25/month for Premium (dev/testing, 4 concurrent requests, any model size), or $75+/month for Scale (production, 8+ concurrent requests with private infrastructure)—and that's it, no surprises on your bill. The tradeoff is that concurrency is capped per tier rather than scaling automatically with demand, so you'll want to match your plan to your peak parallel workload.
What does "unlimited" actually mean in practice? It means your tokens are uncapped—your research team can experiment with 100 different models at varying token volumes and pay the same flat rate. No billing complexity, no cost tracking headaches, and no anxiously watching usage meters climb. The practical constraint is concurrency, not volume: you can process as many tokens as you want, but you're limited in how many requests run simultaneously. For most development and research workflows, this is a non-issue. For production workloads with bursty traffic, the Scale tier's 8+ concurrent slots (or higher on custom plans) provide the headroom you need.
They support over 25,000 models—Llama 4 variants, Mistral, Qwen, and pretty much every other open-source model family you can think of. That breadth matters because you're never locked in; if your needs change, you just switch models without any pricing renegotiation.
Under the hood, it's all serverless—you don't manage GPUs, deal with utilization, or worry about scaling. Your code makes API calls, and the platform handles the rest (model loading, batching, hardware allocation). That means you avoid the overhead of reserved capacity and idle time that come with self-hosted setups.
Featherless.ai is backed by notable investors including Panache Ventures, Airbus Ventures, 500 Global, Kickstart, and Oakseed. The team focuses on production reliability, API stability, and performance rather than racing to the cheapest per-token rate. For developers prioritizing predictability and simplicity over microsecond latency optimizations, flat-rate pricing removes a significant operational burden.
The partnership with Hugging Face provides direct access to the latest open-source models as they're released, ensuring you're never using outdated versions. The platform also supports fine-tuned models, enabling organizations to host proprietary models within the same flat-rate structure.
Comparing Feature Sets Beyond Price
Raw pricing tells only part of the story. Feature differences justify some price variation and matter significantly for developer experience.
Latency and Performance. Fireworks AI and Together.ai advertise sub-100ms latency for common models through inference optimizations. Featherless.ai prioritizes throughput and reliability over absolute minimum latency, typical of serverless platforms. For applications where 50ms latency variations matter (interactive chat), specialized providers might justify higher costs. For batch processing, content generation, or applications with sub-second requirements that can tolerate 200ms latency, the difference is irrelevant.
Rate Limiting and Concurrency. Per-token providers often impose rate limits that scale with your spend tier, sometimes requiring negotiation for higher throughput. Featherless.ai takes a different approach: concurrency is explicit and tied to your subscription tier—2 concurrent requests on Basic, 4 on Premium, and 8+ on Scale. You know exactly what you're getting upfront, with no surprise throttling. For teams that need more, Scale plans can be customized with additional concurrent slots.
Model Diversity. OpenRouter offers access to models from dozens of providers through a unified API. This matters if you want to quickly compare outputs across Claude, GPT, and open-source models without managing separate integrations. Together.ai focuses on open-source depth, offering extensive fine-tuning options. Featherless.ai emphasizes breadth with 25,000+ models, capturing the full spectrum of open-source development.
Enterprise Features. AWS Bedrock includes compliance certifications, VPC support, and dedicated tenancy options valuable for enterprises. These features don't appear in consumer-focused providers and justify enterprise pricing premiums.
Developer Experience. Documentation quality, community support, and ease of integration vary substantially. OpenRouter is known for clear pricing and straightforward API design. Featherless.ai emphasizes transparent documentation and responsive support without vendor complexity.
Customization and Fine-Tuning. Together.ai excels at fine-tuning support, enabling organizations to adapt models to specific domains. Featherless.ai supports fine-tuned models within flat-rate pricing, providing flexibility without per-token overage charges.
Data Sovereignty and Privacy. This is worth thinking about if you work in regulated industries or handle EU customer data. Some providers log prompts and responses, which can raise compliance questions under GDPR and similar regulations. Featherless.ai takes a different approach here—they offer a no-logging policy, so your prompts and outputs aren't stored after the API call. For teams building in healthcare, finance, or any space where data handling matters, this can simplify compliance conversations. It's worth asking every provider: what happens to my data after an API call?
When Per-Token Pricing Still Wins
Despite the appeal of flat-rate pricing, per-token providers remain best for specific scenarios.
Minimal Usage. If your entire application processes 10,000 tokens monthly, paying $10–25 monthly flat-rate is wasteful. Per-token pricing at $0.00055/1K tokens costs roughly $0.006. This advantage disappears quickly as usage grows, but for academic projects, hobby experiments, and internal tools with minimal traffic, per-token wins.
Premium Model Access. GPT-5 mini, Claude Opus 4.6, and other frontier models are primarily available through per-token pricing. If your application demands their specific capabilities, you have no alternative. However, before accepting this cost, genuinely evaluate whether open-source alternatives perform acceptably; many applications built assuming you need GPT-5 mini actually perform equivalently with Mistral or Llama.
Predictable Lightweight Traffic. Applications with steady, known token volumes and modest requirements can optimize per-token pricing carefully. A production service processing exactly 1M tokens daily with Fireworks AI costs roughly $201/year, beating Featherless.ai's $99/month option if your requirements never expand. The risk: as your application grows, flat-rate pricing often becomes the smarter long-term choice.
Multi-Provider Strategy. Some applications worth billions can negotiate per-token pricing below public rates, effectively becoming cheaper than flat-rate options. This requires scale and negotiating use unavailable to most startups.
FAQ: Questions About LLM Pricing in 2026
Q: Is per-token pricing cheaper than flat-rate?
A: It depends on your volume. For volumes under ~50K tokens daily with open-source models, per-token can be cheaper. Above that threshold, flat-rate typically wins by 2-10x. For larger volumes with proprietary models, per-token has no competitive alternative.
Q: Will inference prices keep dropping?
A: Yes. Inference costs have declined 30-50% annually for open-source models since 2023, and this trend continues as hardware improves and providers optimize. Building with flexible provider selection ensures you can capture these reductions.
Q: What hidden costs should I worry about most?
A: Cold start latency, egress charges, and GPU idle time for reserved instances are the biggest hidden cost culprits. Account minimums and lock-in provisions matter less for startups but become significant at scale.
Q: Can I switch providers without code changes?
A: Not entirely. Most providers follow OpenAI's API format, enabling partial compatibility. However, response formats, model names, and features differ enough that meaningful code changes are necessary. Using abstraction layers (like LangChain) reduces switching friction but doesn't eliminate it.
Q: Is open-source model quality good enough?
A: For 80-90% of use cases, yes. Mistral and Llama match or exceed GPT-5 mini's capabilities on many benchmarks. Edge cases with complex reasoning, multimodal processing, or domain-specific tasks still favor frontier models. Testing your specific requirements against various models reveals the truth for your use case.
Q: Should I self-host models to avoid inference costs?
A: Rarely. Self-hosting requires managing infrastructure, scaling, monitoring, and updates. Total cost of ownership including engineer time typically exceeds managed providers within months, unless you have extraordinary scale or specialized requirements.
Q: How do I estimate costs during development?
A: Log tokens on a test customer cohort, then extrapolate to full user base. Most applications see 20-40% variance from estimates; building models with 50% buffer protects against surprises.
Q: What's the fastest way to reduce inference costs?
A: Switch to smaller open-source models (if feasible for your use case), implement prompt caching for repeated contexts, and batch non-urgent inference. These three tactics often cut costs 50-80%.
Q: What about data privacy and sovereignty?
A: Worth checking the fine print on this one. Many providers log prompts and completions for model training or debugging, which can be a problem if you handle sensitive data or fall under GDPR. Some providers like Featherless.ai offer a no-logging policy, meaning your prompts and outputs aren't stored after the API call. It's worth checking every provider's data handling policy before committing.
Conclusion
The 2026 inference market offers more options than ever. Flat-rate providers like Featherless.ai give you access to 25,000+ models at predictable costs, removing much of the infrastructure overhead that used to justify pricier proprietary options. Per-token providers still make sense for specific use cases, but they're no longer the automatic default.
Your best choice depends on usage patterns, model requirements, and organizational priorities. Research teams benefit from flat-rate flexibility. Production applications with steady traffic and modest models often achieve best economics with per-token providers, though flat-rate increasingly wins as scale grows. Applications requiring frontier models default to per-token pricing until open-source alternatives mature further.
One approach worth considering: start with Featherless.ai's flat-rate pricing for development and initial deployment, evaluate per-token providers once you have real usage data, and periodically reassess as new providers emerge and pricing evolves. The market moves fast, so flexibility matters—build with minimal vendor lock-in, keep an eye on pricing trends, and be ready to migrate when better alternatives appear.
To start optimizing your inference costs today, try Featherless.ai's platform and experience serverless open-source LLM access with no token limits. The Premium tier provides access to thousands of models for just $25/month with 4 concurrent request slots—enough for most development and benchmarking workflows. Your fastest path to inference cost optimization begins with understanding your actual usage patterns, and Featherless's flat-rate structure lets you explore them without cost anxiety. When you're ready to scale, the Scale tier offers 8+ concurrent slots and private infrastructure for production workloads.
Last Updated: March 4, 2026
Disclaimer: Pricing information reflects publicly available rates as of March 2026. Provider pricing changes frequently; verify current pricing with each provider before making infrastructure decisions. The examples and cost calculations are approximate and intended for illustrative purposes; actual costs depend on specific usage patterns, model choices, and regional variations.
Related articles
Start building under 3 minutes





