What if we could get the fixed-cost inference of linear RNNs and the flexible, high-fidelity memory of full softmax attention in the same architecture?
That is the motivation behind Key-Value Means, or KVM. KVM keeps the familiar shape of a Transformer key-value cache, but treats part of that cache as an expandable recurrent state. The result is a smooth trade-off: you can choose how much memory and compute to spend as context length grows, rather than choosing between a fixed-size state and a full KV cache.

The problem: fixed memory or growing memory
Modern linear RNNs and state-space-style models such as RWKV, Gated DeltaNet, and Mamba have an enormous advantage at inference time: they keep a fixed-size state. The millionth token can be processed for about the same cost as the thousandth token, and the model does not need to keep a KV cache that grows with context length.
The downside is that fixed memory is fixed memory. Once the state is full, new information must overwrite, merge with, or otherwise interfere with old information. Even worse, the memory size usually has to be chosen up front, often before pretraining.
Transformers sit at the opposite extreme. They grow a KV cache with every token. That gives them excellent recall and an almost embarrassingly direct mechanism for long-context memory: keep the keys and values, and attend over them later. But the cost grows with sequence length. Storage grows linearly with context length, and so does the cost of computing attention for each new decoded token.
It seems like there should be a middle ground: a way to decide, continuously, how much memory to keep and how much compute to spend. KVM is the missing piece of that puzzle.
The core idea
KVM starts from a simple question:
What if a Transformer-style key-value cache could expand on demand, instead of expanding once per token?
Softmax attention works extremely well, so KVM tries hard not to throw it away. Instead, it stores compressed long-range memory in a form that still looks like keys and values. Queries can then attend over both:
1. a recent block sliding window of ordinary tokens, and
2. a compressed, optionally growing KVM state.
The model still performs one softmax attention operation over keys and values. The difference is that old tokens do not necessarily remain as one cache row per token. Some are merged into existing state rows; the most novel ones can be appended as new state rows.
That gives KVM a continuum of behavior:
KVM can therefore behave like a chunked RNN, like a sublinear-memory long-context model, or like something closer to attention, depending on the state-growth schedule.
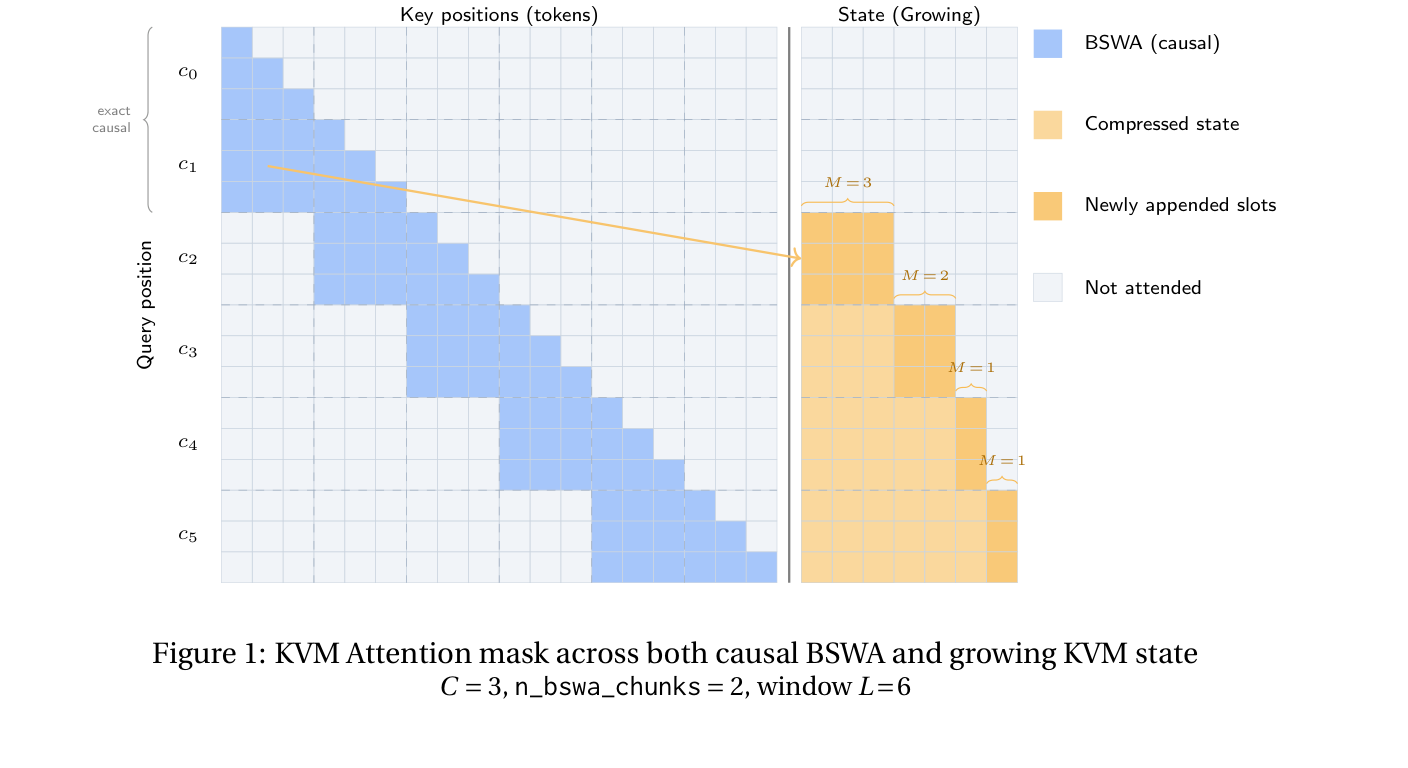
Why block sliding window attention matters
Several test-time-training and recurrent-state architectures update their state in batches. That is attractive because state updates can be amortized across many tokens. Instead of updating a recurrent state for every token, the model updates once per chunk.
But batching creates an immediate question: what happens to the tokens generated between state updates?
A common answer is to combine attention over state with a sliding window over recent tokens. That works, but a token-level sliding window can overlap awkwardly with chunk boundaries. Tokens can spend part of their life in the local window and then get compressed later, which makes it easy to double count or create boundary artifacts.
KVM uses Block Sliding Window Attention (BSWA) instead. The local window advances one chunk at a time. When a block falls out of the window, that same block is compressed into state.

This gives KVM a clean lifecycle for each token:
1. while recent, it is visible exactly in the BSWA window;
2. when its chunk leaves the window, it is either appended to state or merged into state;
3. after that, it is represented only through the compressed state.
No token needs to be represented twice.
Starting the state
The first chunk gives KVM an elegant base case. Before anything has overflowed, there is no compressed state. So KVM simply uses the first chunk of keys and values to initialize the state directly.

This is a useful sanity check: if the state is initialized from real key-value rows and the next chunks are still in the BSWA window, then early KVM behavior closely resembles ordinary softmax attention over a small prefix. From there, each later overflow block can be handled by the same append-or-merge recurrence.
Merging: each overflow token chooses one state row
Once a chunk overflows the BSWA window, KVM must compress it into state.
The key observation is that the key is already the vector attention uses for matching. So KVM uses key similarity to decide where an overflow token belongs. For each overflow key, it compares that key against the current state keys. The most similar state key wins.
In other words, KVM uses a winner-take-all assignment:
merge_target(token j) = argmax_i similarity(overflow_key_j, state_key_i)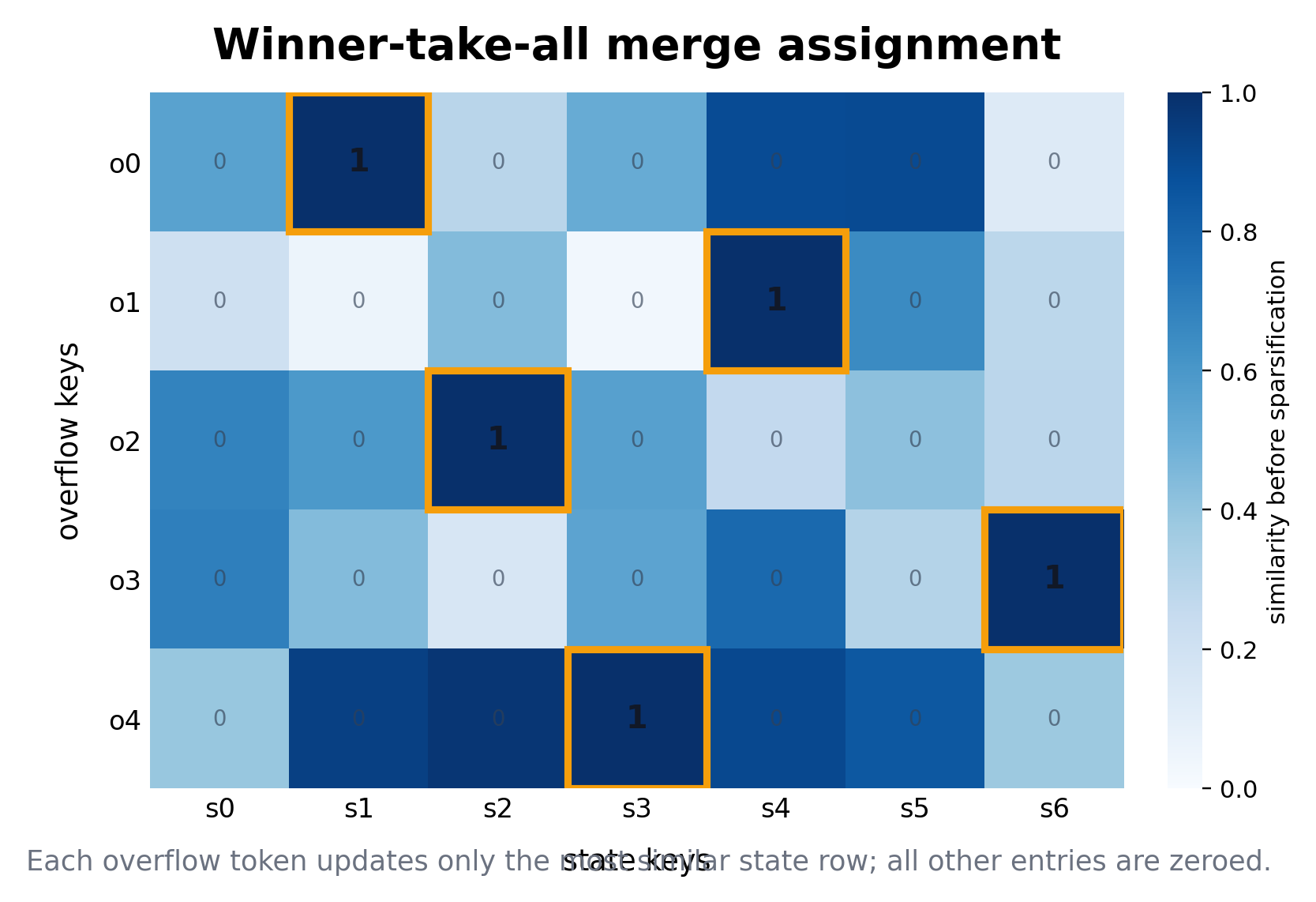
This sparsity turned out to matter. Softer assignments spread each incoming token across many state rows, which can blur the state. Winner-take-all merging instead encourages different state rows to stay separated. The intuition is that separability is capacity: if state keys remain distinct, the model has more usable memory slots.
Updating a state row
After an overflow token chooses a state row, KVM updates the selected key and value with a gated addition. In simplified form:
s_key[i] <- s_key[i] + g_j * overflow_key[j]
s_value[i] <- s_value[i] + g_j * overflow_value[j]
More precisely, KVM merges all overflow tokens assigned to a state row in one chunked update:
s_key[i] <- s_key[i] + sum_{j: target(j)=i} g_j * key_bar[j]
s_value[i] <- s_value[i] + sum_{j: target(j)=i} g_j * value[j]
The gate g_j is data dependent. It lets the model modulate how strongly each incoming token should affect the compressed memory.
This update behaves like a weighted running average, but without separately tracking token counts. That is where KVM's normalization trick becomes important.
Just-in-time normalization
If you average vectors, the resulting vector often gets shorter. Orthogonal components cancel in length; opposing components can destructively interfere. If a state row keeps absorbing tokens, its raw vector norm may become a poor representation of how it should participate in attention.
KVM solves this with just-in-time normalization, or JIT norm.
The underlying state keeps an accumulated running sum. But immediately before attention, KVM uses a normalized version of that state. The normalized version is used for readout; the underlying state is not overwritten by the normalization.
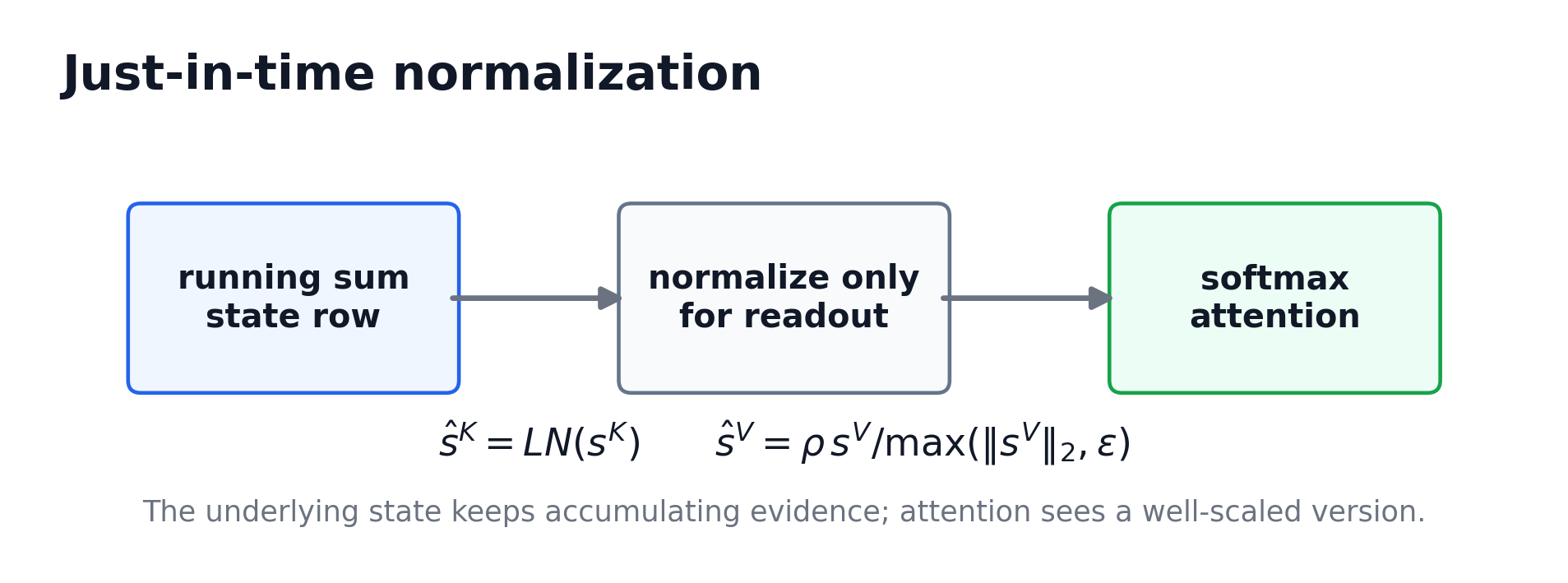
This has two benefits:
1. the state update remains simple; and
2. the attention mechanism sees well-scaled keys and values.
For values, KVM stores a readout radius when a state row is created. At readout time, the value direction can change through merging, while the value norm is restored to the row's stored radius. This helps preserve the special behavior of sink-like rows and prevents value magnitudes from collapsing.
Growing the state: append the surprising tokens
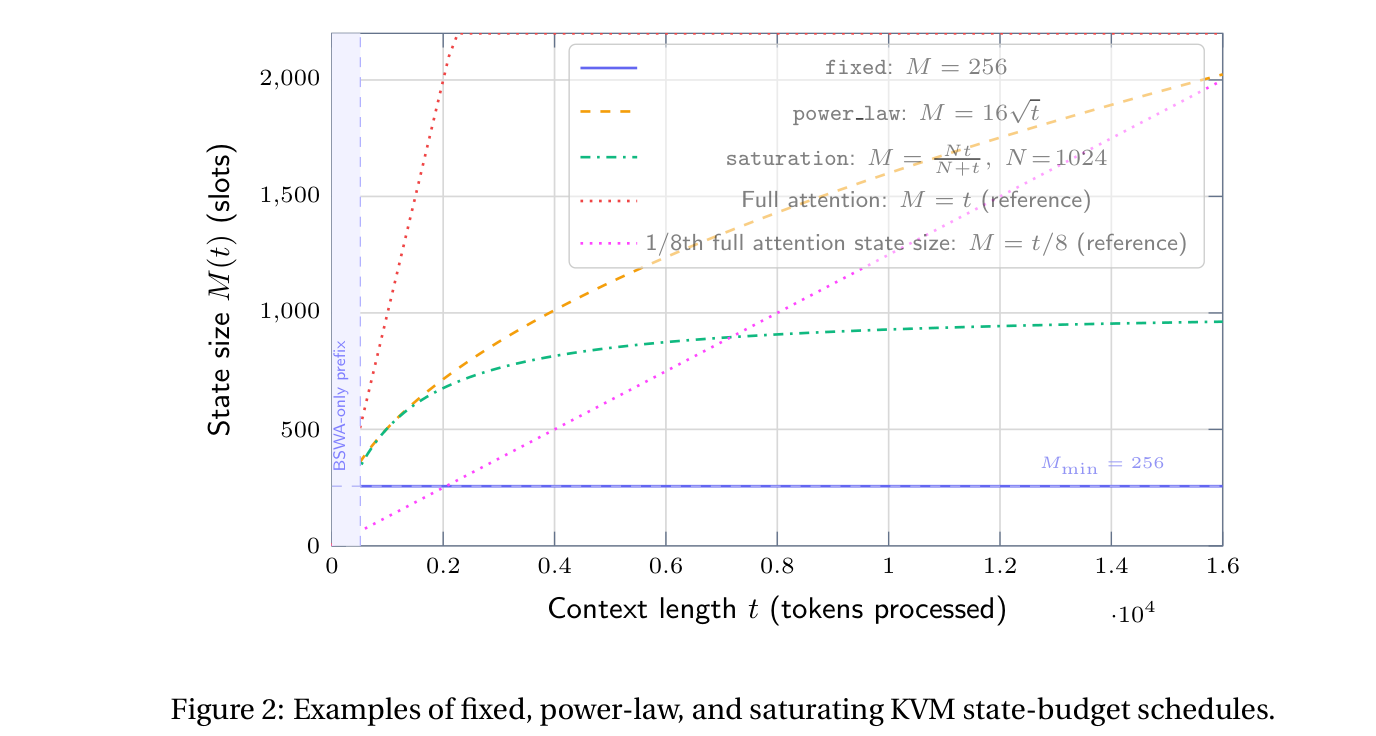
A fixed-size KVM state already gives a useful chunked recurrent architecture. But the more interesting version lets the state grow.
KVM appends the overflow tokens that are least redundant with the current state. The same key-similarity calculation used for merging can measure redundancy: if an overflow token has no high-similarity match in the current state, it is surprising. KVM appends the most surprising tokens and merges the rest.

This creates a simple growth rule:
1. compute each overflow token's maximum similarity to the current state;
2. sort overflow tokens by that maximum similarity;
3. append the least-similar, most novel tokens until the current state budget is reached;
4. merge the remaining overflow tokens into the expanded state.
The state budget can be fixed, power-law, saturating, or learned in future variants. In the paper, a simple 16√N schedule works well: the state grows sublinearly with sequence length, giving much better long-context recall than a fixed state while still using a decreasing fraction of the full KV cache.
Positional encoding: RoPE for the window, NoPE for the state
A compressed state is not a normal sequence anymore. A state row may contain information merged from tokens at many different positions. Assigning it a single RoPE position would be artificial and could make the key mean different things depending on where it originally came from.
KVM therefore uses a hybrid positional strategy:
- the BSWA region uses partial RoPE, preserving short-range ordering where it matters most;
- before keys are merged into state, the RoPE channels are zeroed;
- the state behaves more like NoPE memory, which is better suited to position-independent compressed content.
This is an important part of making KVM a single attention mechanism over two regions: a local, position-aware region and a compressed, position-independent region.
Readout: one softmax over window plus state
At readout time, KVM concatenates the normalized state keys and values with the current BSWA keys and values. Attention is then performed over the combined memory.
That means the query can choose between recent exact tokens and older compressed state rows inside one softmax. No separate attention layer, no gated addition between state and window outputs, and no special readout mechanism are required.
The paper also uses learned per-head temperature scalars for the state and BSWA regions. This lets each head tune how sharply it attends to compressed memory versus recent exact tokens.
Results: long-context behavior without full KV growth
The KVM experiments train 120M and 350M parameter models at 8K context length on Prolong. The models are then evaluated at longer positions on TextbookChapters and on long-context benchmarks such as RULER, NIAH subsets of RULER, and LongBench.
The position-wise loss result is the most direct picture of the trade-off. KVM maintains strong loss as position increases, even beyond the 8K training context. The growing-state KVM variant, using the 16√N schedule, is especially strong: it is the best non-GPTAlpha model in the TextbookChapters extrapolation test, and it matches or beats non-hybrid GPTAlpha beyond the trained context length.
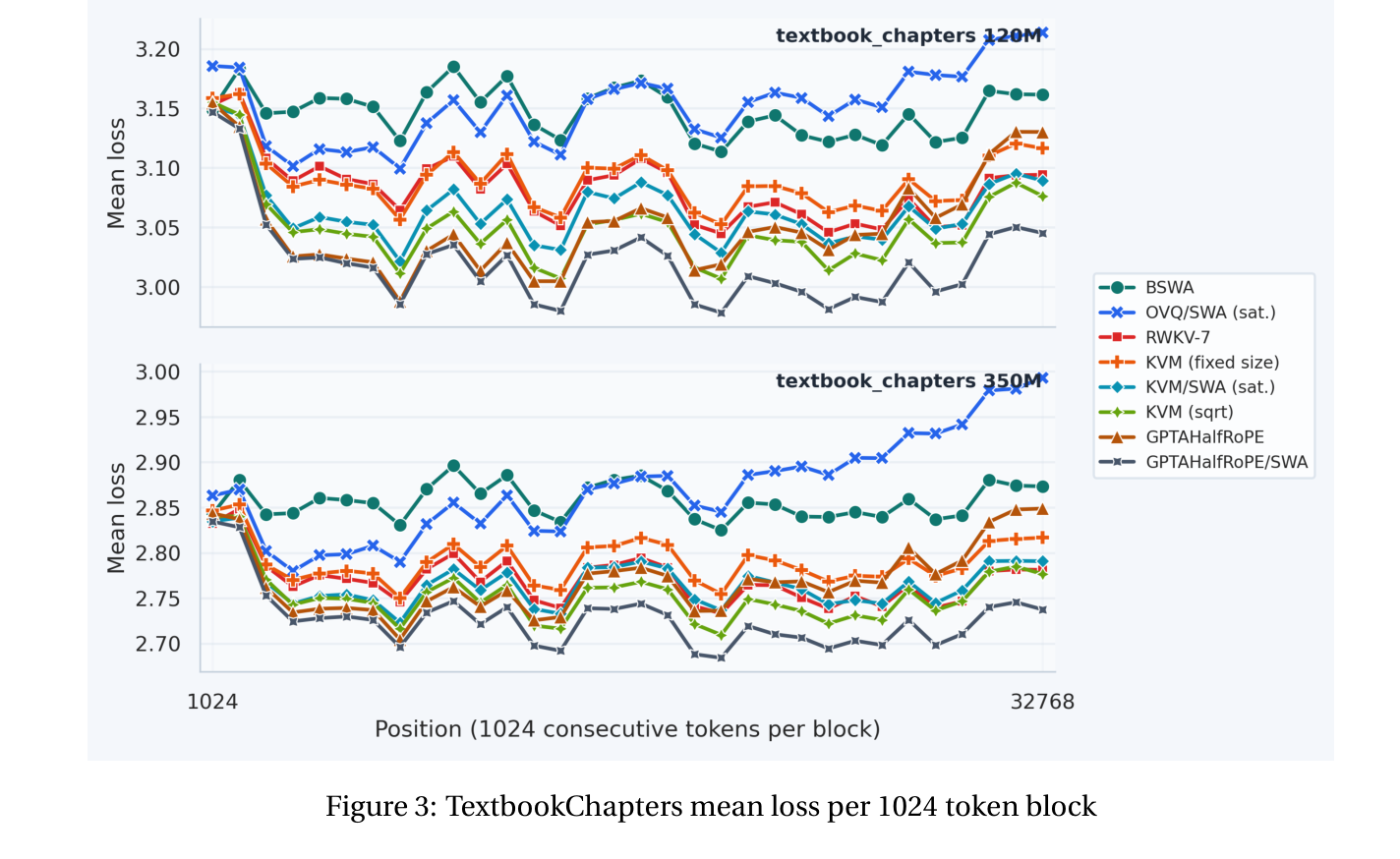
The benchmark results show the same broad pattern, with an important nuance:
- Fixed KVM state can do very well when the task does not require preserving a continuously novel distractor stream. For example, the 350M fixed-state KVM remains strong on NIAH-S1 even at 32K.
- Growing KVM state helps when the context contains more unique information. On the harder NIAH variants with essay-like distractors, fixed-state methods degrade much more sharply, while the √N KVM keeps substantially better recall.
- Short-context performance stays competitive. Because KVM still has ordinary attention over the BSWA window, tasks that fit inside that window behave much like they do for a normal Transformer-style model.
The ablations are also telling. Removing value-length normalization causes the largest long-context degradation. Removing sink protection and the merge gate also hurts. These results suggest that the details of state readout and update are not cosmetic; they are central to making compressed memory usable.
Minimal pseudocode
The core recurrence is short. This is not implementation-complete, but it captures the conceptual loop:
for chunk in sequence_chunks:
# 1. Attend over normalized state + current BSWA window.
state_k_read = normalize_state_keys(state_k)
state_v_read = normalize_state_values(state_v, stored_value_radius)
out = softmax_attention(
q=current_queries,
k=concat(state_k_read * tau_state, bswa_keys * tau_bswa),
v=concat(state_v_read, bswa_values),
mask=state_plus_causal_bswa_mask,
)
# 2. Identify the block that just fell out of the BSWA window.
overflow_k, overflow_v = get_overflow_block()
# 3. Prepare keys for position-independent memory.
memory_k = layernorm(zero_rope_channels(overflow_k))
gate = 1 + elu(x @ W_merge_gate)
gated_k = gate * memory_k
gated_v = gate * overflow_v
# 4. Append the least-redundant overflow tokens if the budget grew.
novelty = -max_similarity(memory_k, normalize_state_keys(state_k))
append_ids = top_k(novelty, num_to_append)
state_k, state_v = append_selected_rows(state_k, state_v, memory_k, overflow_v, append_ids)
# 5. Merge the rest into their nearest state rows.
merge_ids = overflow_ids - append_ids
targets = argmax_similarity(gated_k[merge_ids], normalize_state_keys(state_k))
state_k = scatter_add(state_k, targets, gated_k[merge_ids])
state_v = scatter_add(state_v, targets, gated_v[merge_ids])
In an optimized implementation, the recurrence can be computed chunk-wise and the attention can be issued as a single masked attention operation over the state and BSWA regions.
Why this is exciting
KVM is interesting because it does not ask us to abandon attention. Instead, it changes how the KV cache grows.
A standard Transformer says: every token gets a cache row forever.
A fixed-state RNN says: the state size is fixed forever.
KVM says: keep exact recent tokens, compress older tokens into key-value-shaped memory, and expand that memory when the content is novel enough or when the schedule allows it.
That opens up a wide design space:
- fixed-size KVM as a strong O(N) chunked recurrent attention layer;
- sublinear-growth KVM for long contexts with bounded memory pressure;
- hybrid models that combine KVM with linear RNN layers;
- content-driven state expansion instead of static schedules;
- cross-layer shared memory;
- distillation from pretrained full-attention Transformers into KVM attention.
The biggest conceptual shift is that memory size becomes a runtime and architecture choice, not a binary decision made by selecting either full attention or an RNN.
Final thoughts
In a world where long-context models often force a choice between fixed-size compressed state and linearly growing KV caches, Key-Value Means offers a third path. It keeps the softmax-attention interface that makes Transformers powerful, but gives the memory a recurrent, expandable structure.
We have only scratched the surface of what this enables. The current paper uses simple state-growth schedules and straightforward merge rules, but the framework naturally invites more adaptive strategies: learned expansion thresholds, task-dependent memory budgets, cross-layer state sharing, and distillation from large pretrained attention models.
The most important point is simple: KVM turns the KV cache from an unavoidable cost into a controllable resource.
Links
- Paper: https://arxiv.org/abs/2605.09877
- Code: github.com/recursal/KVM-paper
- Models: huggingface.co/collections/recursal/key-value-means
Related articles
Start building under 3 minutes





